Repeated Prisonners Dilemma
This section summarizes the SequentialPrisonersDilemma project, where two independently trained PPO agents repeatedly play a Prisoner's Dilemma game. The goal is to test whether learned behavior converges to persistent defection, cooperative conventions, or mixed horizon-dependent patterns.
Environment and Learning Setup
- Environment:
envs/prisoners_dilemma_env.py - Agents:
player_1andplayer_2 - Actions:
0 = cooperate,1 = defect - Training algorithm: PPO (RLlib 2.54.0)
- Training style: independent learning with separate policies
Payoff matrix per round:

Episodes run with a fixed horizon n_sequential_games, so each episode is a finite repeated game.
Research Question and Hypotheses
The core question is whether independent PPO self-play recovers backward-induction-like defection in finite-horizon repeated play.
- H1 (game-theoretic target): behavior approaches early, persistent defection.
- H2 (RL behavior): cooperation may survive for substantial parts of an episode, with possible end-game defection or stable cooperative pockets.
A key caveat from the repository: independent PPO is not an equilibrium solver, so convergence to a Nash-consistent outcome is not guaranteed.
Evaluation Strategy
The project reports:
- cooperation/defection rates,
- mean episode return,
- mean rounds per episode,
- multi-seed stability,
- unilateral defection-gain checks against fixed opponents.
It also includes two robustness workflows:
stability_sweep: checks variance and stability across random seeds.sweep_n_sequential_pd: measures how cooperation changes as horizon length changes.
Main Reported Fixed-Horizon Result (50 rounds)
The README reports that for n_sequential_games = 50, both agents converge to all-defect behavior in evaluation:
mean_episode_reward:player_1 = 50.0,player_2 = 50.0cooperation_rate:player_1 = 0.0,player_2 = 0.0mean_rounds_per_episode:50.0
This matches the finite-horizon all-defect baseline where each round yields (D, D) -> (1, 1).
Sweep Results: Cooperation vs Number of Repeated Games
The repository also reports a broader sweep across n_sequential_games = 5..100 (step 5), using 20 seeds and 95% confidence intervals.
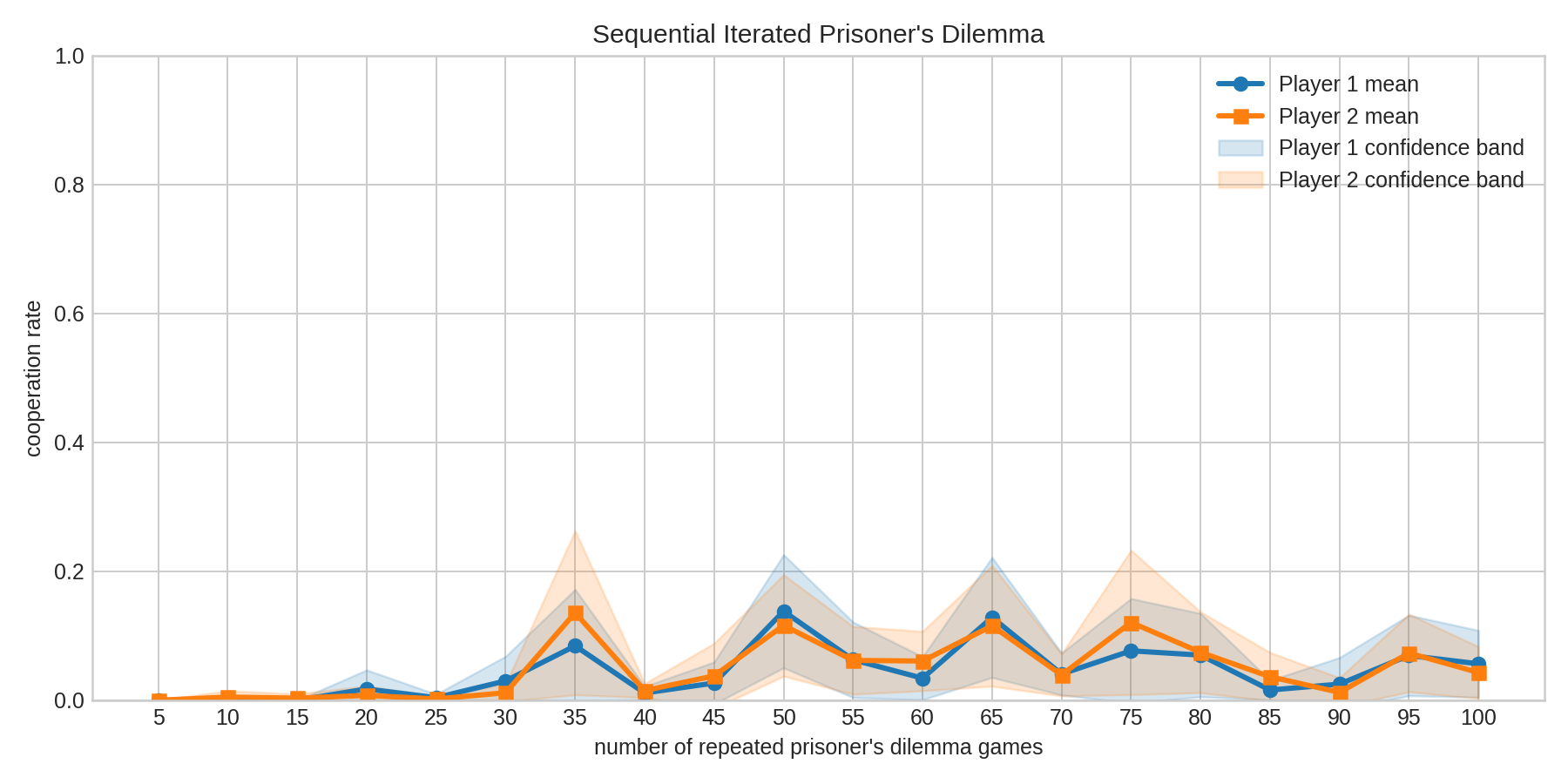
Key observations summarized from the README:
- Cooperation is not uniformly zero across horizons.
- Higher-cooperation pockets appear around
n=35,50,65, and75. - Low-cooperation settings remain (
n=5,10,15,25). - Under two-sided testing with Holm correction over 40 tests, no
(horizon, player)result was significant atalpha = 0.05in the shown run.
Interpretation
The reported pattern is non-monotonic: cooperation can reappear at specific horizons even when all-defect dominates at others. This suggests independent PPO self-play can produce horizon-dependent learned conventions rather than a single robust equilibrium profile.
Practical Takeaways
- Finite-horizon all-defect remains an important baseline and does emerge in some settings.
- Multi-seed analysis is necessary because single-seed outcomes can be misleading.
- Horizon length materially changes behavior, so it should be treated as a first-class experimental variable.
- Defection-gain checks are useful to test whether a policy pair is resistant to unilateral deviation.
Limitations Noted by the Project
- Independent PPO optimizes against moving opponents and does not directly solve for Nash fixed points.
- Cooperation estimates are seed-sensitive at many horizons.
- Statistical correction across many tests can remove apparent single-condition significance.
Overall, the project supports a careful conclusion: in repeated social dilemmas, learned cooperation under independent PPO is possible but conditional, unstable across parts of parameter space, and strongly affected by episode horizon.
Where to Go Next
If you want to continue from this MARL bridge toward broader cooperation questions:
- Selected Cooperation Theory for inherited, across-generation dynamics.
- Learning-Selection Interaction Theory for the full nature-nurture coupling.
- Cooperation (Social Behavior) for a broader behavioral framing.