Predator-Prey-Grass base environment
The base environment consists of two species: predator and prey. Both species are seperately trained, resulting into two separate policies.
Features base environment
-
At startup Predators, Prey and Grass are randomly positioned on the gridworld.
-
Predators and Prey are independently (decentralized) trained via their own RLlib policy module.:
- Predators (red)
- Prey (blue)
-
Energy-Based Life Cycle: Movement, hunting, and grazing consume energy—agents must act to balance survival, reproduction, and exploration.
-
Predators and Prey learn movement strategies based on their partial observations.
-
Both expend energy as they move around the grid and replenish energy by eating:
- Prey eat Grass (green) by moving onto a grass-occupied cell.
- Predators eat Prey by moving onto the same grid cell.
-
Survival conditions:
- Both Predators and Prey must act to prevent starvation (when energy runs out).
- Prey must act to prevent being eaten by a Predator
-
Reproduction conditions:
- Both Predators and Prey reproduce asexually when their energy exceeds a threshold.
- New agents are spawned near their parent.
-
-
Sparse rewards: agents only receive a reward when reproducing in the base configuration. However, this can be expanded with other rewards in the environment configuration. The sparse rewards configuration is to show that the ecological system is able to sustain with this minimalstic optimized incentive for both Predators and Prey.
-
Grass gradually regenerates at the same spot after being eaten by Prey. Grass, as a non-learning agent, is being regarded by the model as part of the environment, not as an actor.
Training and evaluation results
Training the agents and evaluating the environment is an example of how elaborate behaviors can emerge from simple rules in MARL models. As pointed out earlier, rewards for learning agents are solely obtained by reproduction. So all other reward options are set to zero in the environment configuration. Find more background on this reward shaping and scaling here. Despite this relatively sparse reward structure, maximizing these rewards results in elaborate emerging agents behaviors such as:
- Predators hunting Prey
- Multiple Predators colaborating/competing hunting Prey; increasing the probability of Prey being caught
- Prey finding and eating grass
- Predators hovering around grass to ambush Prey
- Prey trying to escape Predators
Moreover, these learning behaviors lead to more complex emergent dynamics at the ecosystem level:
-
The trained policies make the ecosystem perpetuate much longer than a random policy.
-
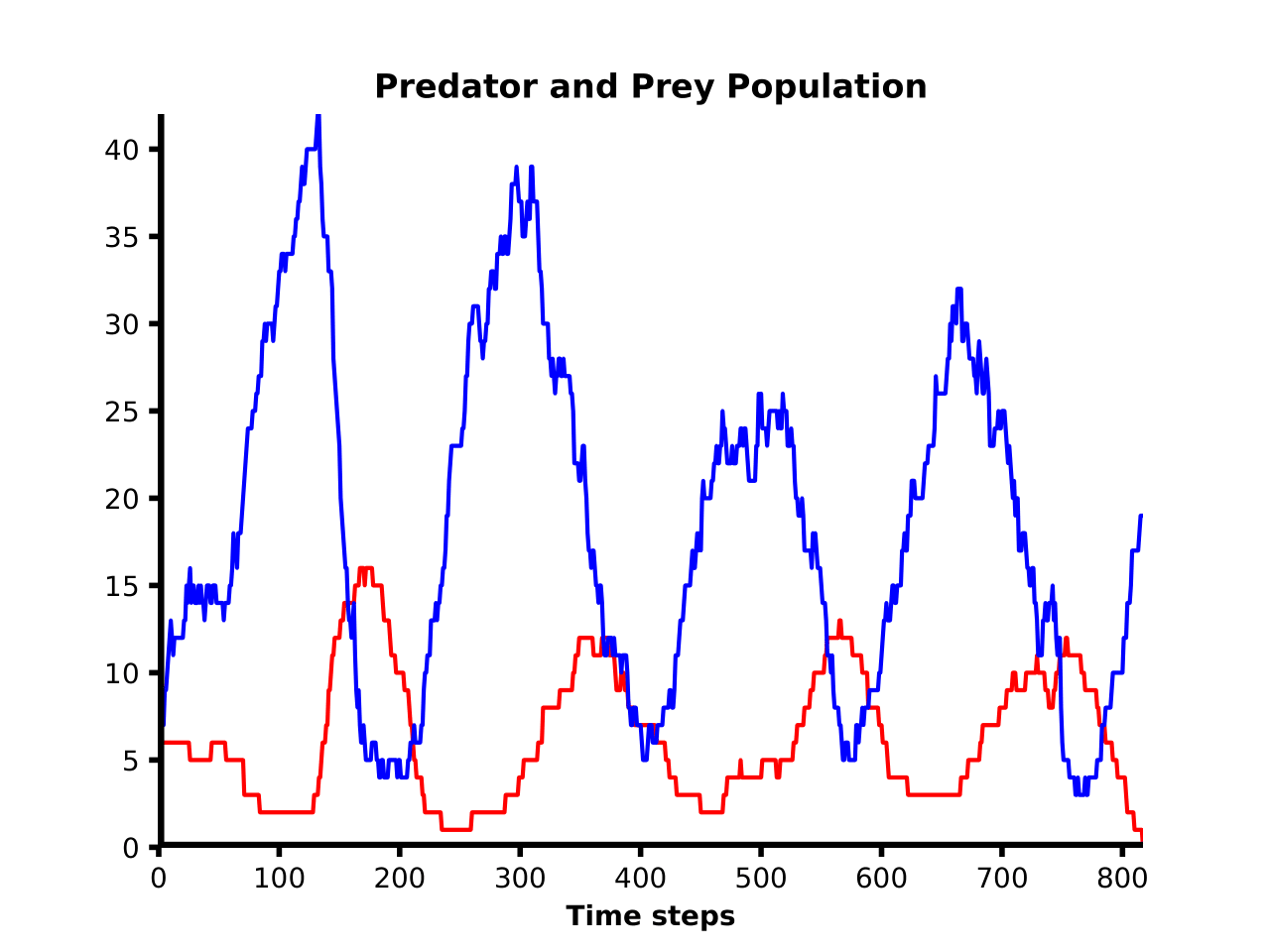
The trained agents are displaying a classic Lotka–Volterra pattern over time:
Centralized versus decentralized training
The described environment and training concept is implemented with seperated (decentralized) training for both learning agent types utilizing the RLlib framework. To elaborate on the difference, we compare this approach with the (legacy) centralized trained environment utilizing PettingZoo and Stable Baselines3 (SB3).
(Legacy) Configuration of centralized training
The MARL environment predpregrass_base.py is implemented using PettingZoo, and the agents are trained using Stable-Baselines3 (SB3) PPO. Essentially this solution demonstrates how SB3 can be adapted for MARL using parallel environments and centralized training. Rewards (stepping, eating, dying and reproducing) are aggregated and can be adjusted in the environment configuration file. Basically, Stable Baseline3 is originally designed for single-agent training. This means in this solution, training utilizes only one unified network for Predators as well Prey. See here in more detail how SB3 PPO is used in the Predator-Prey-Grass multi-agent setting.
Decentralized training: Pred-Prey-Grass MARL with RLlib new API stack
Obviously, using only one network has its limitations as Predators and Prey lack true specialization in their training. The RLlib new API stack framework is able to circumvent this limitation elegantly. The environment dynamics of the RLlib environments are largely the same as in the PettingZoo environment. However, newly spawned agents are placed in the vicinity of the parent, rather than randomly spawned in the entire gridworld. The implementation under-the-hood of the setup is somewhat different, utilizing array lists to store agent data rather than implementing a separate agent class (largely a result of attempting to optimize compute time of the step function). Similarly as in the PettingZoo environment, rewards can be adjusted in a separate environment configuration file
Training is applied in accordance with the RLlib new API stack protocol. The training configuration is more out-of-the-box than the PettingZoo/SB3 solution, but nevertheless is much more applicable to MARL in general and especially decentralized training.
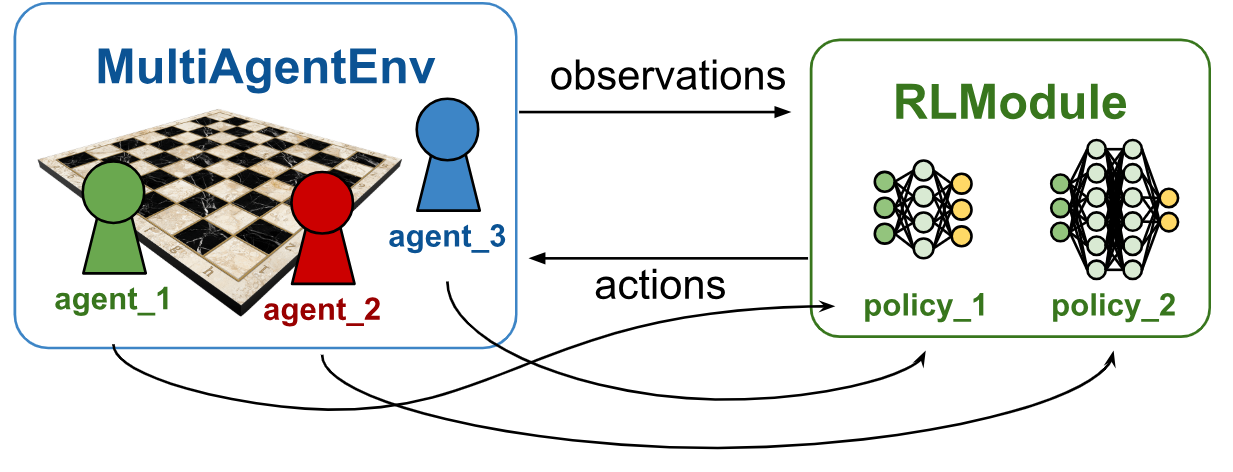
A key difference of the decentralized training solution with the centralized training solution is that the concurrent agents become part of the environment rather than being part of a combined single "super" agent. Since, the environment of the centralized training solution consists only of static grass objects, the environment complexity of the decentralized training solution is dramatically increased. This is probably one of the reasons that training time of the RLlib solution is a multiple of the PettingZoo/SB3 solution.