Model 1 - Trust Learning
Model 1 (two_timescale_reciprocity.py) is the baseline two-timescale model: agents update a scalar trust value per partner within a lifetime, and evolution selects on the inherited parameters that shape that learning.
Key findings
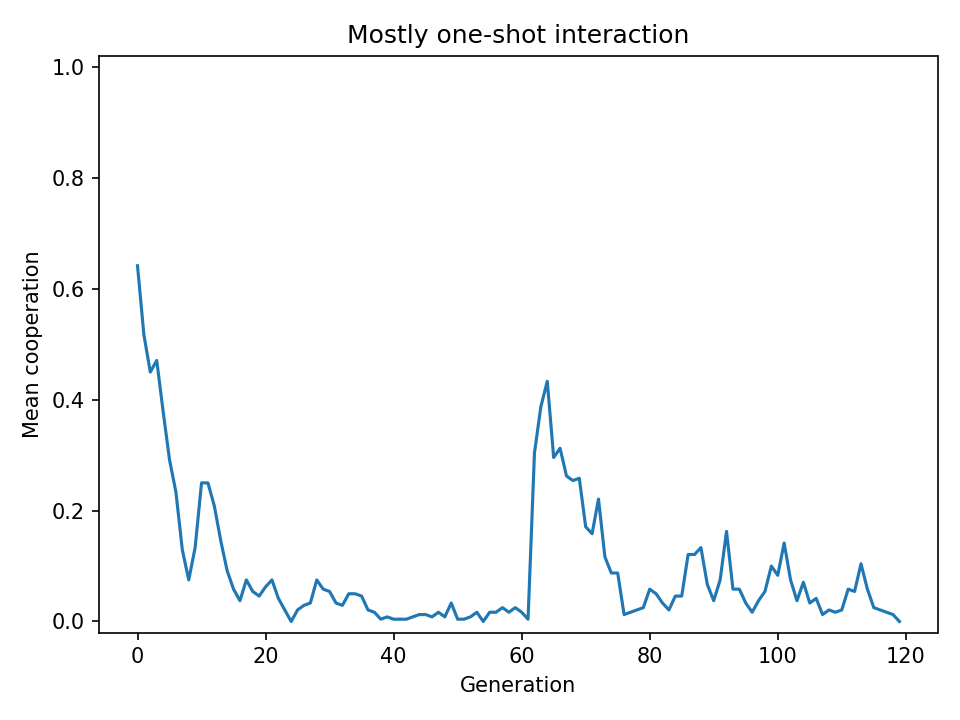
- In one-shot interaction, cooperation collapses to zero. Selection drives
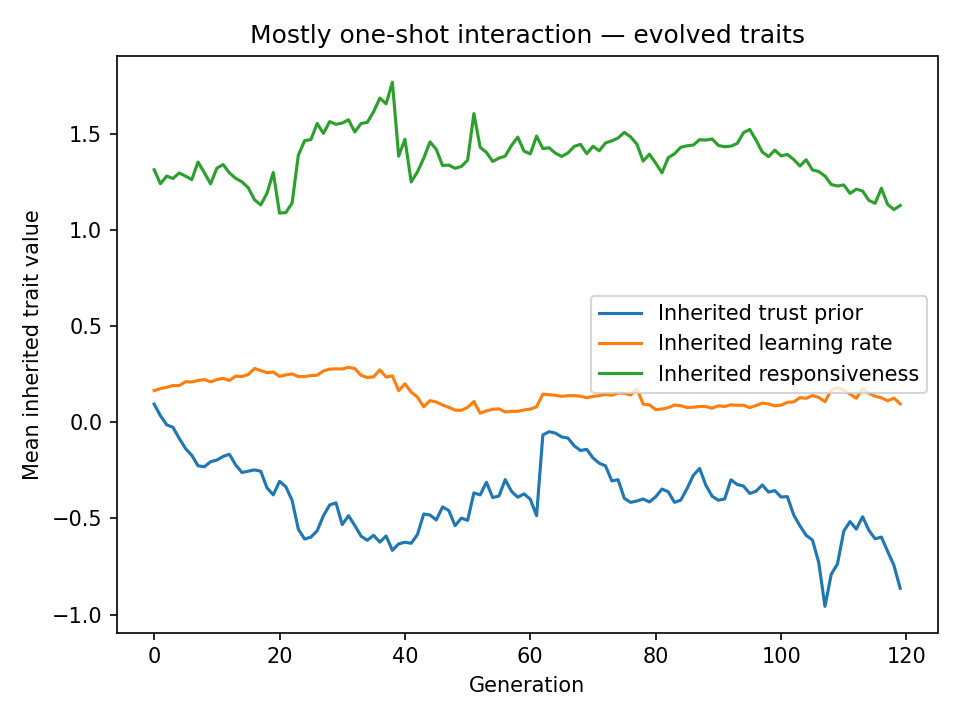
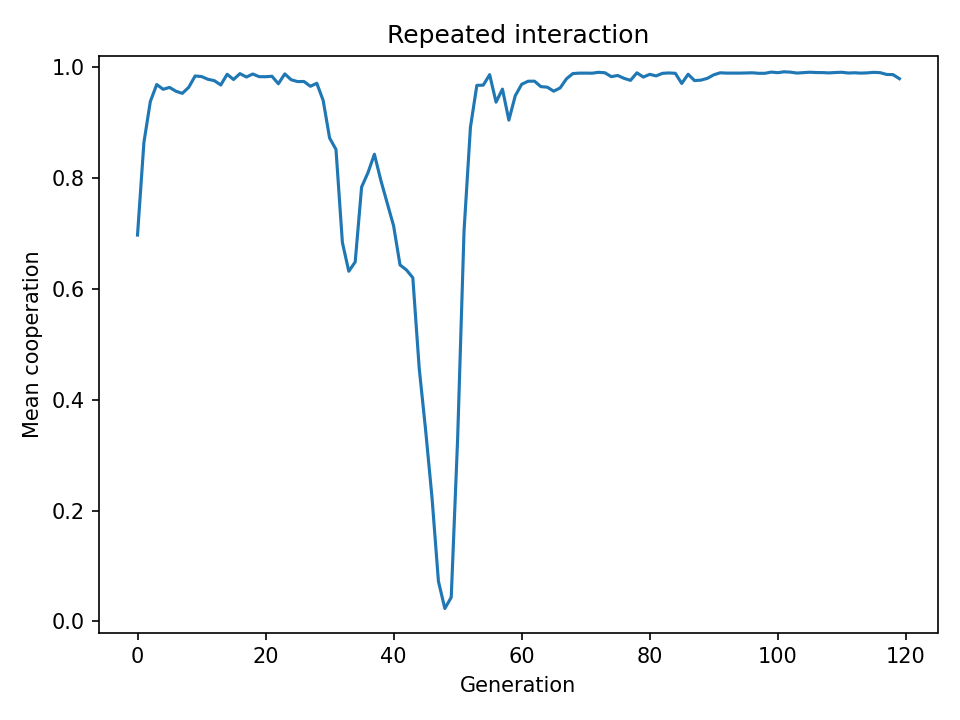
trust_priorstrongly negative (−0.86) — innate suspicion is favored because unconditional cooperators are exploited with no chance to learn. - In repeated interaction (80 rounds), cooperation stabilises near 98% within ~40 generations.
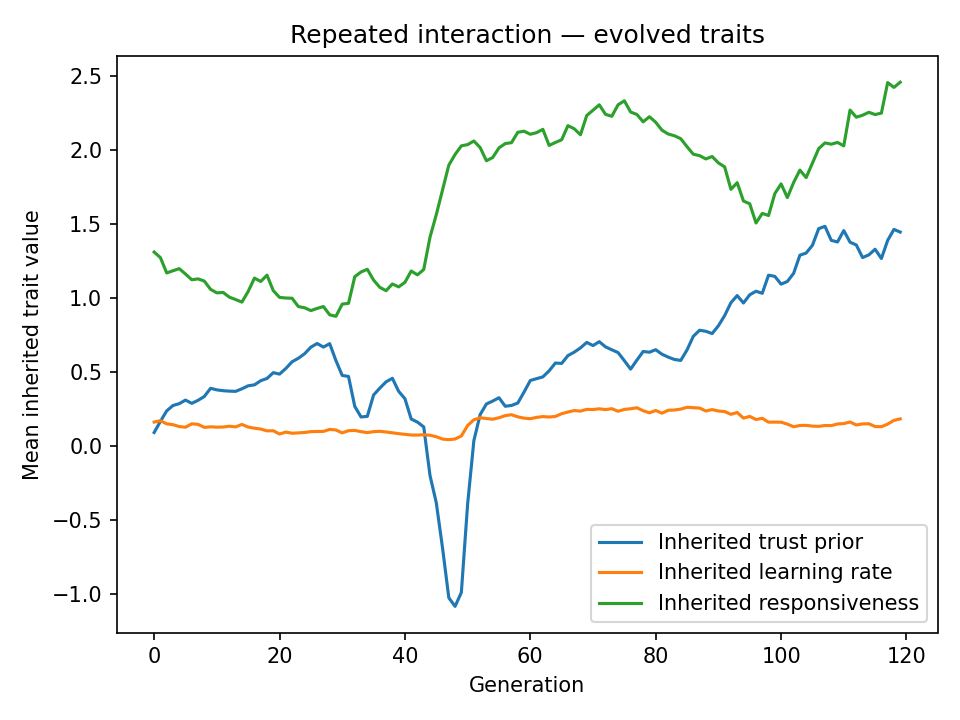
responsivenessis the decisive evolved trait (~2.46 in repeated play): agents who amplify learned trust sharply reward cooperators and punish defectors, locking in the reciprocal equilibrium.learning_ratestays low (~0.19) in both conditions — fast forgetting is not favored because stable trust relationships are valuable.- The two timescales reinforce each other: evolution shapes the parameters that make learning effective, and learning produces the cooperation signal that selection acts on.
Learning during a lifetime
Each agent tracks partner-specific trust:
learned_trust[i, j]
The decision score combines inherited tendency and learned partner history:
score_i = trust_prior[i] + responsiveness[i] * learned_trust[i, j]
cooperate_i = score_i > 0.0
The trust update rule follows a Rescorla–Wagner style prediction-error update — see Appendix: Rescorla–Wagner style learning.
Evolution between generations
Agents reproduce proportional to lifetime payoff. Offspring inherit and mutate:
trust_priorlearning_rateresponsiveness
Payoff structure
Donation-game defaults:
benefit = 3.0cost = 1.0
For ecological interpretation of why benefit can exceed cost in this abstraction, see Appendix: Ecological realism of benefit > cost.
For one-shot versus repeated scenario rationale, see Appendix: Why compare one-shot and repeated interaction?.
Cooperation theory context: For how this model relates to direct/network reciprocity and which mechanisms are out of scope, see Appendix: Cooperation mechanisms and model scope.
Results summary
| Metric | One-shot (rounds=1) | Repeated (rounds=80) |
|---|---|---|
| Final cooperation rate | 0.000 | 0.979 |
| Final mean payoff | 0.000 | 313.300 |
| Final trust prior | −0.864 | 1.447 |
| Final learning rate | 0.095 | 0.186 |
| Final responsiveness | 1.126 | 2.459 |
One-shot interaction
Without repeated contact, agents cannot learn who cooperates. Reciprocity never gets off the ground and cooperation collapses to zero.
Repeated interaction
With 80 rounds per generation, cooperation stabilises near full (~98%).
Summary
In one-shot interaction, cooperation collapses to zero. Evolution responds by driving trust_prior negative (−0.86): selection favors innate suspicion because unconditional cooperators are exploited. responsiveness stays moderate but is effectively irrelevant when there is nothing useful to learn in a single round.
In repeated interaction, cooperation stabilises near 98%. trust_prior rises to ~1.45 — selection favors agents who start out cooperative, because unconditional cooperators seed mutual cooperation with neighbors. responsiveness rises strongly to ~2.46 — agents who amplify what they have learned become sharply conditional, strongly rewarding cooperators and punishing defectors, reinforcing the reciprocal equilibrium.
The dip around generation 45–55 is a classic invasion event. A defector lineage briefly spreads, trust collapses, and cooperation crashes. The population recovers because reciprocators with high responsiveness re-establish cooperation faster than defectors can spread.
The two timescales reinforce each other in the repeated case. Learning makes cooperation individually rational within a lifetime. Evolution then favors the inherited traits (trust_prior, responsiveness) that make that learning work most effectively. In the one-shot case, the fast timescale provides no useful signal, so evolution strips away cooperative predispositions entirely.