Model 2 - Q-learning
Model 2 (two_timescale_q_learning.py) keeps the same two-timescale framework as Model 1 but replaces scalar trust with action-value learning, giving agents a more principled reinforcement-learning algorithm.
Key findings
- Repeated-interaction payoff rises to 611 — nearly double Model 1's 313 — because Q-learning agents explicitly price in the future value of a cooperative relationship via the discount factor.
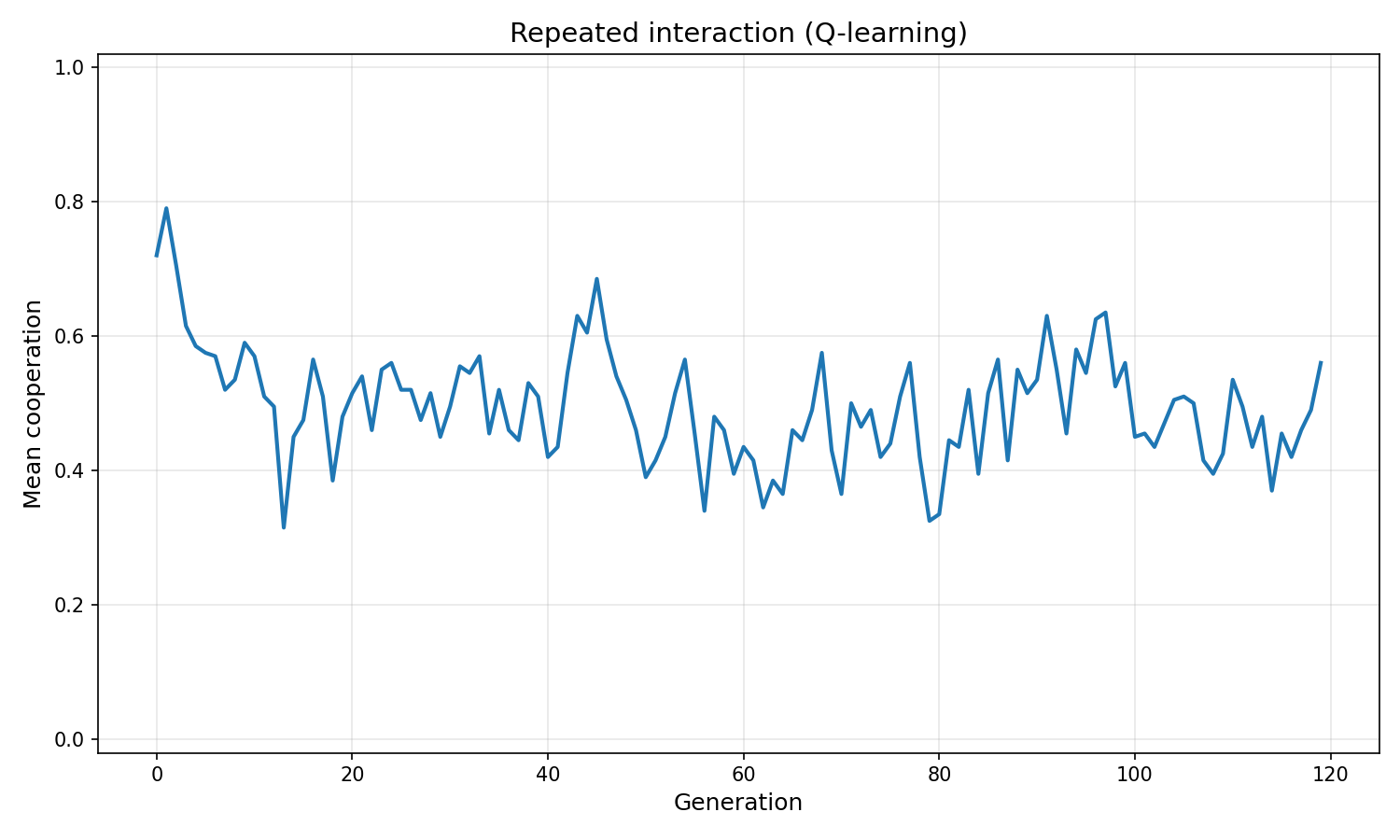
- Repeated cooperation rate is lower than Model 1 (0.56 vs 0.98). Q-learning agents keep exploring (ε ~0.11 at convergence), occasionally defecting to probe partners.
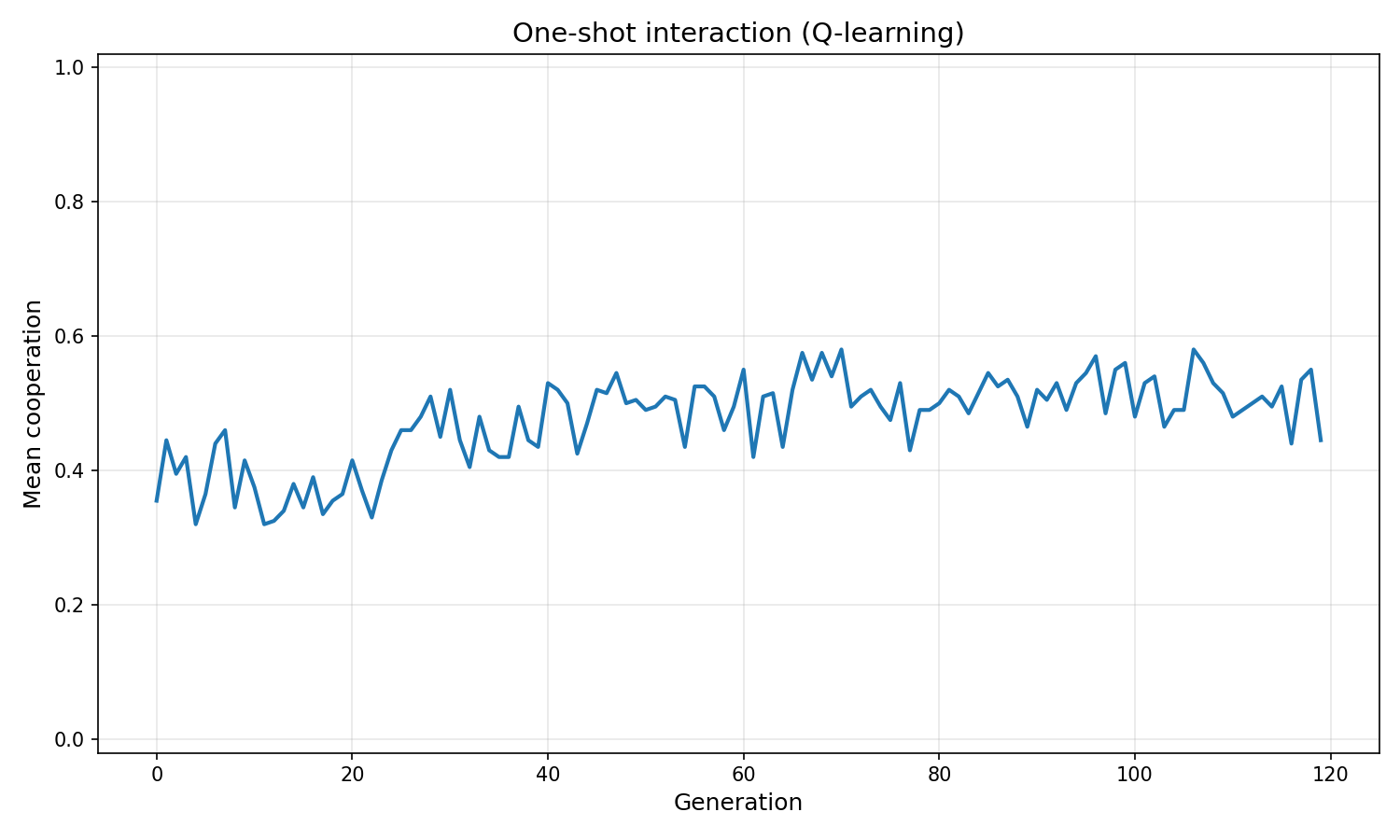
- In one-shot interaction, Q-learning achieves 0.445 cooperation — far above Model 1's zero — because
initial_q_biascan encode a standing cooperative prior without needing learned history. - Trust learning maximises cooperation rate; Q-learning maximises payoff by retaining strategic exploration and leveraging future relationship value.
Learning during a lifetime
Each agent stores partner-specific Q-values for both actions:
Q[i, j, COOPERATE]
Q[i, j, DEFECT]
Updates follow temporal-difference learning:
new Q = old Q + alpha * (reward + gamma * max future Q - old Q)
Action selection is epsilon-greedy: with probability ε the agent tries a random action, otherwise it picks the higher Q-value for that partner.
Evolution between generations
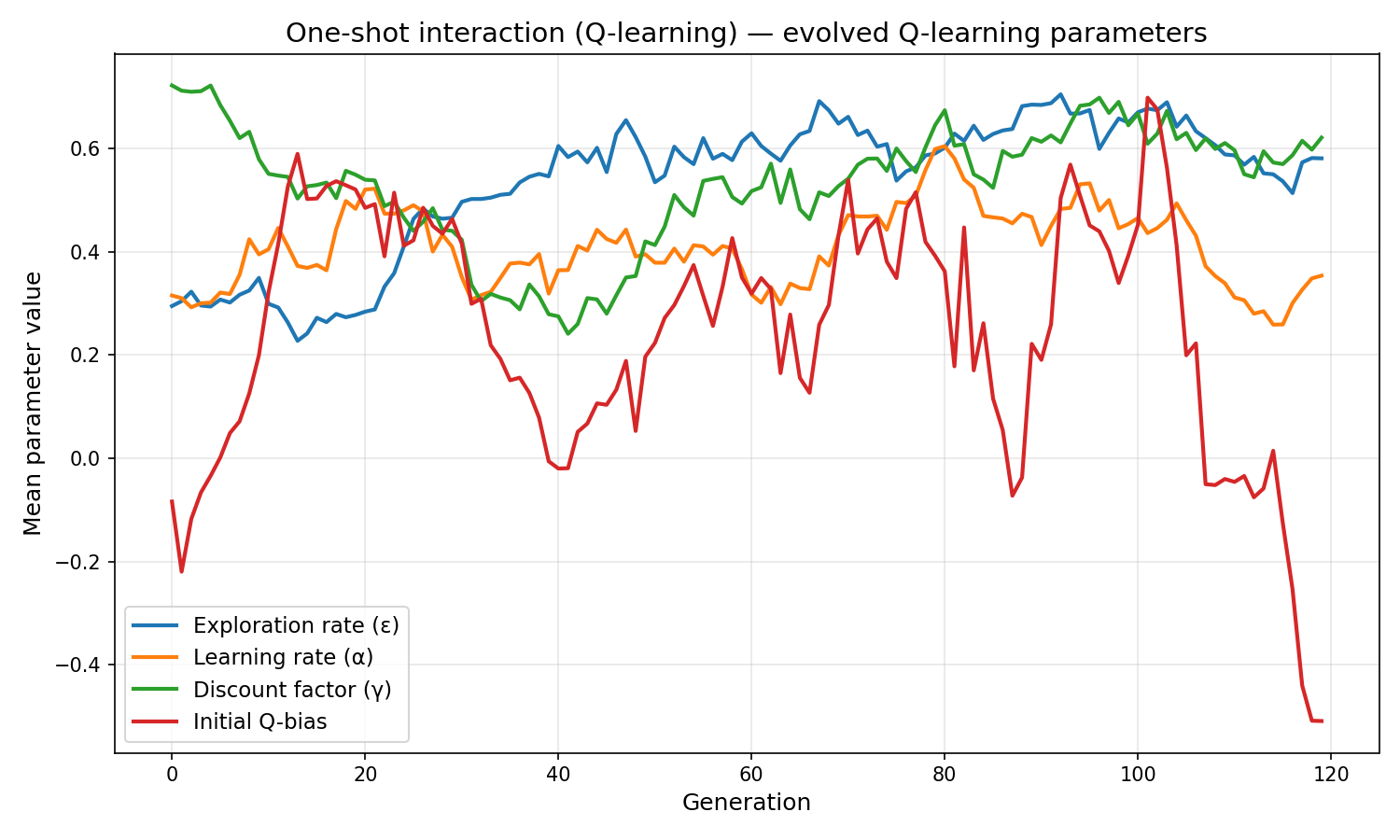
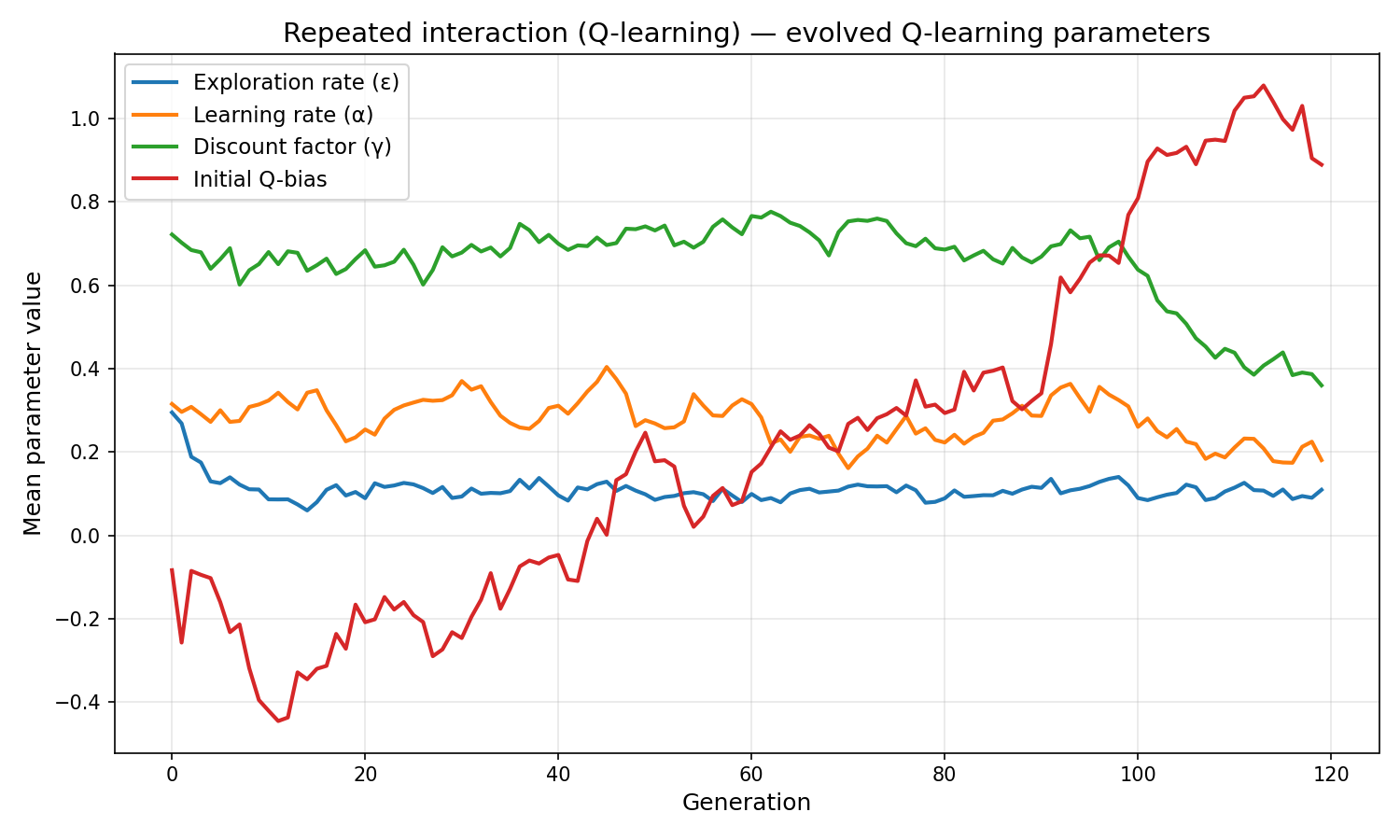
Agents inherit and mutate four RL parameters:
exploration_rate(epsilon)learning_rate(alpha)discount_factor(gamma)initial_q_bias
Results summary
| Metric | One-shot | Repeated |
|---|---|---|
| Final cooperation rate | 0.445 | 0.560 |
| Final mean payoff | 8.150 | 611.350 |
| Final exploration rate | 0.581 | 0.109 |
| Final learning rate | 0.353 | 0.180 |
| Final discount factor | 0.621 | 0.360 |
| Final initial Q-bias | −0.509 | 0.889 |
One-shot interaction
Repeated interaction
Summary
With proper Q-learning, repeated-interaction payoff rises to 611 — nearly double Model 1's 313. Q-learning agents discount the long-term value of the cooperative relationship, not just a single round, making cooperation even more individually rational over time.
Repeated cooperation rate is lower (0.56 vs 0.98). Q-learning agents maintain higher exploration (ε = 0.11) even late in evolution, occasionally defecting to probe partners. The trust-learning model converges to near-universal cooperation because its deterministic threshold eventually locks in high responsiveness. The trade-off is real: trust learning maximises cooperation rate; Q-learning maximises payoff.
Q-learning agents stay strategically selective. They never fully stop exploring — they defect not randomly, but informationally, probing whether a partner is still worth cooperating with. Because γ > 0, they also know a good cooperative relationship has compounding future value, so they actively protect it. Q-learning agents detect and punish defectors faster, value long-term relationships more accurately, and don't blindly cooperate with everyone.
Humans are probably closer to the Q-learning model than the trust model. We don't cooperate unconditionally even with close partners; we maintain low-level vigilance in trusted relationships; we discount the future more heavily in unstable environments and cooperate more when the future feels secure. The high payoff of Q-learning reflects an evolutionary logic: strategic, selective cooperation with future-orientation outperforms both pure defection and unconditional cooperation.
For a deeper analysis of what this trade-off means for human psychology, see Appendix: Strategic and psychological interpretation.