Model 3 - Extended
Model 3 (two_timescale_extended.py) adds three social mechanisms on top of Q-learning: reputation, partner choice (interaction refusal), and forgiveness after betrayal.
Key findings
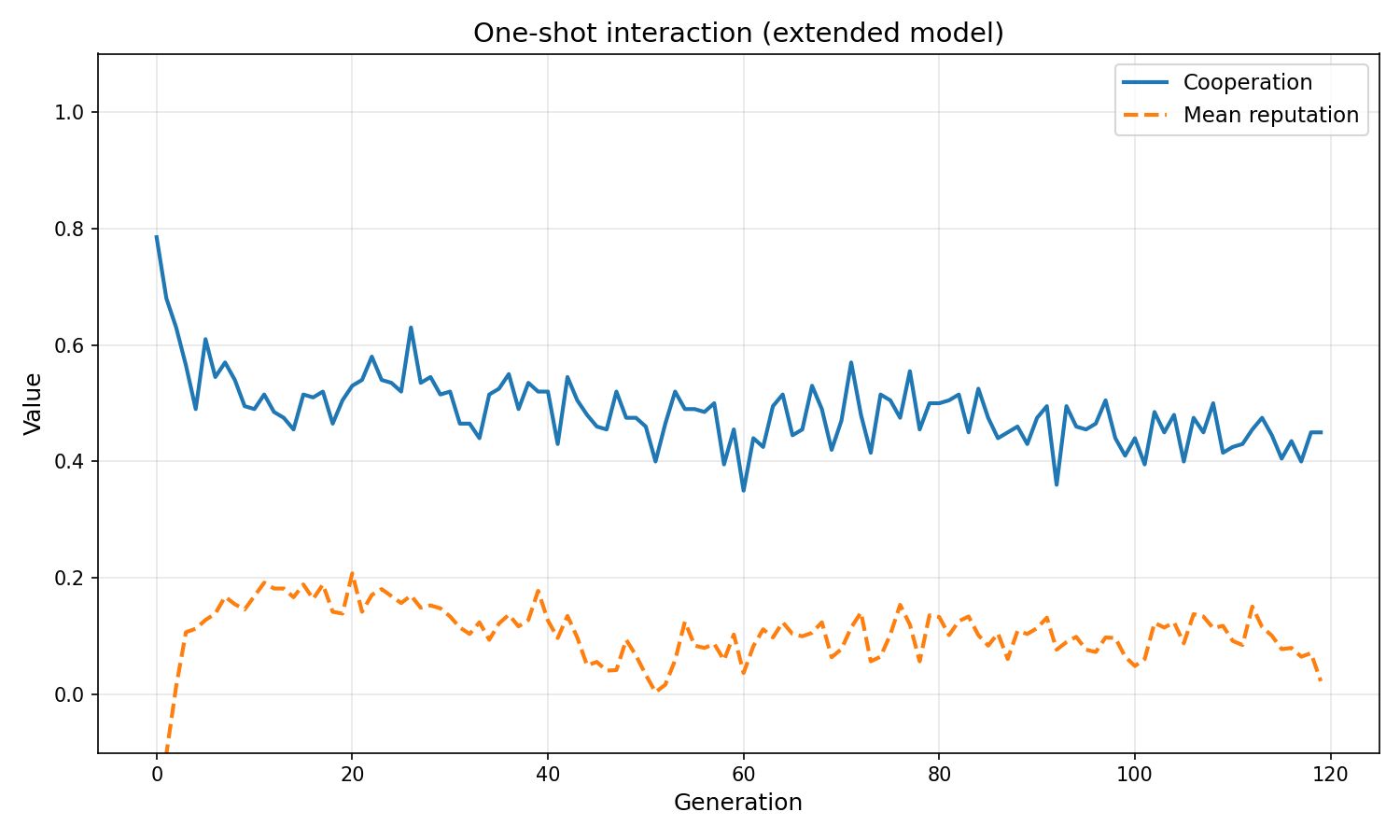
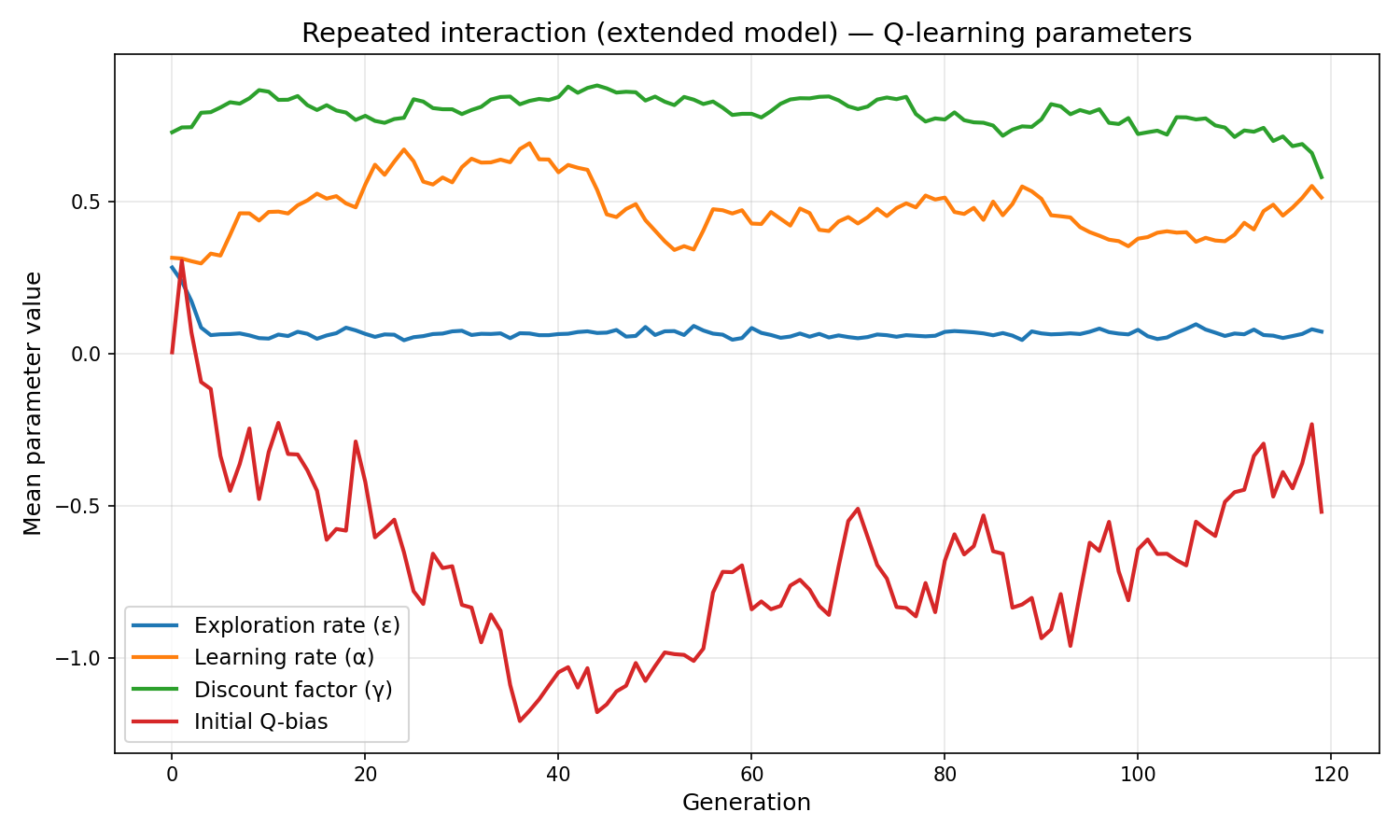
- Cooperation rate is lower than in Model 2 (0.38 vs 0.56) — not a failure, but a shift to conditional cooperation with active monitoring.
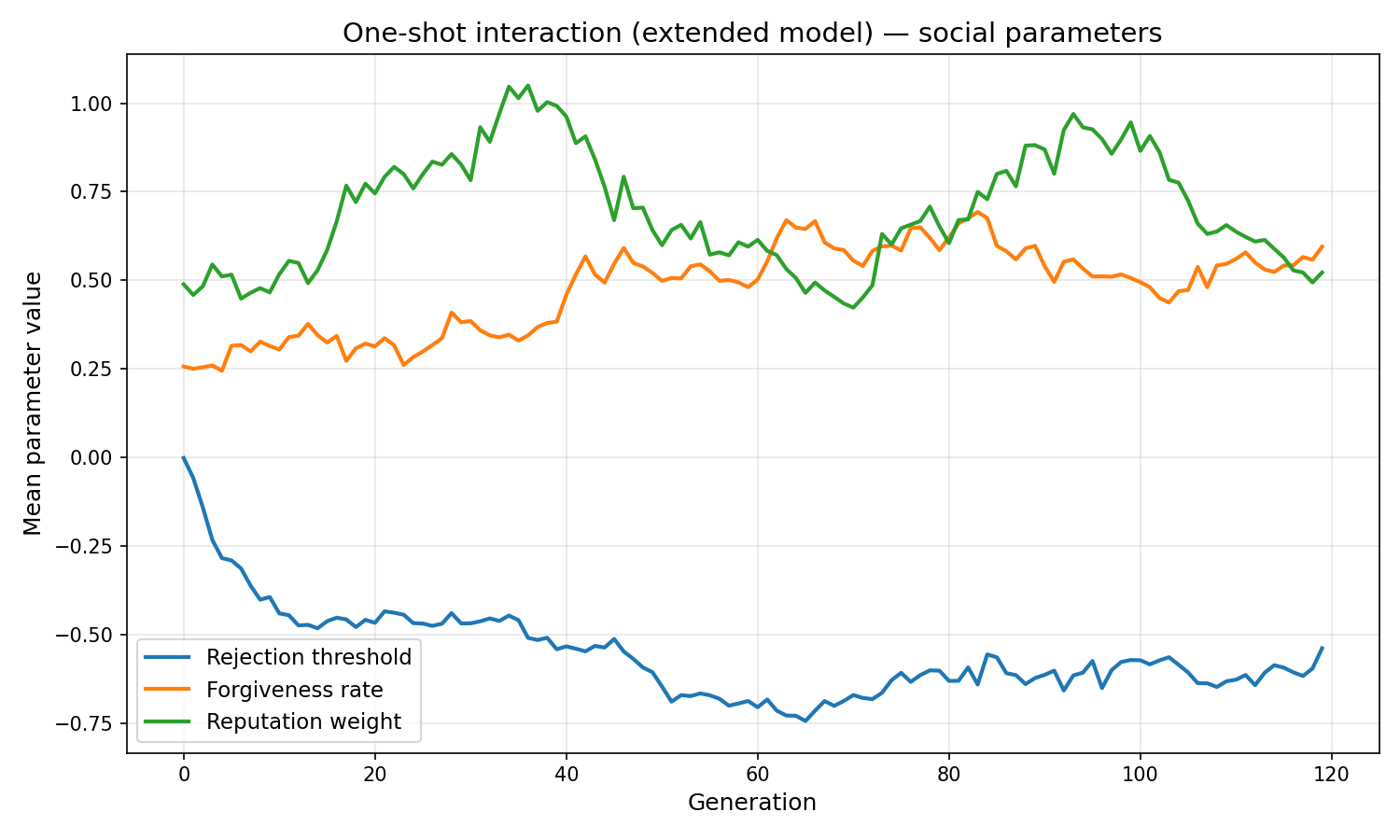
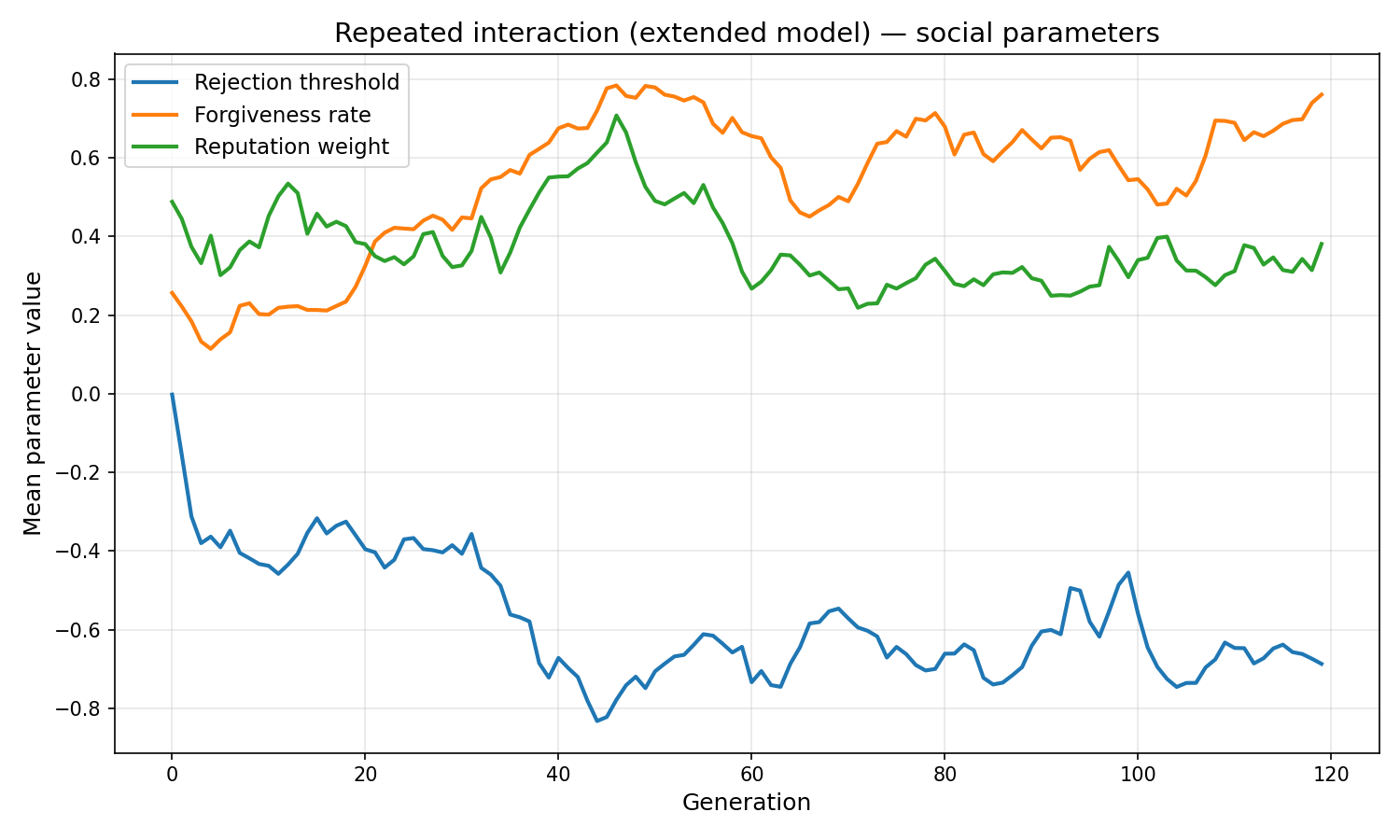
- The rejection threshold evolves to be lenient (−0.69), meaning agents rarely exclude partners. But when they do, excluded agents lose further reputation, which compounds.
- Forgiveness evolves high (0.76 in repeated play) — agents that recover quickly from betrayals maintain more cooperative relationships over time.
- Reputation weight evolves modest (0.38) — public reputation is used as a weak prior for strangers; personal Q-history takes over once direct experience exists.
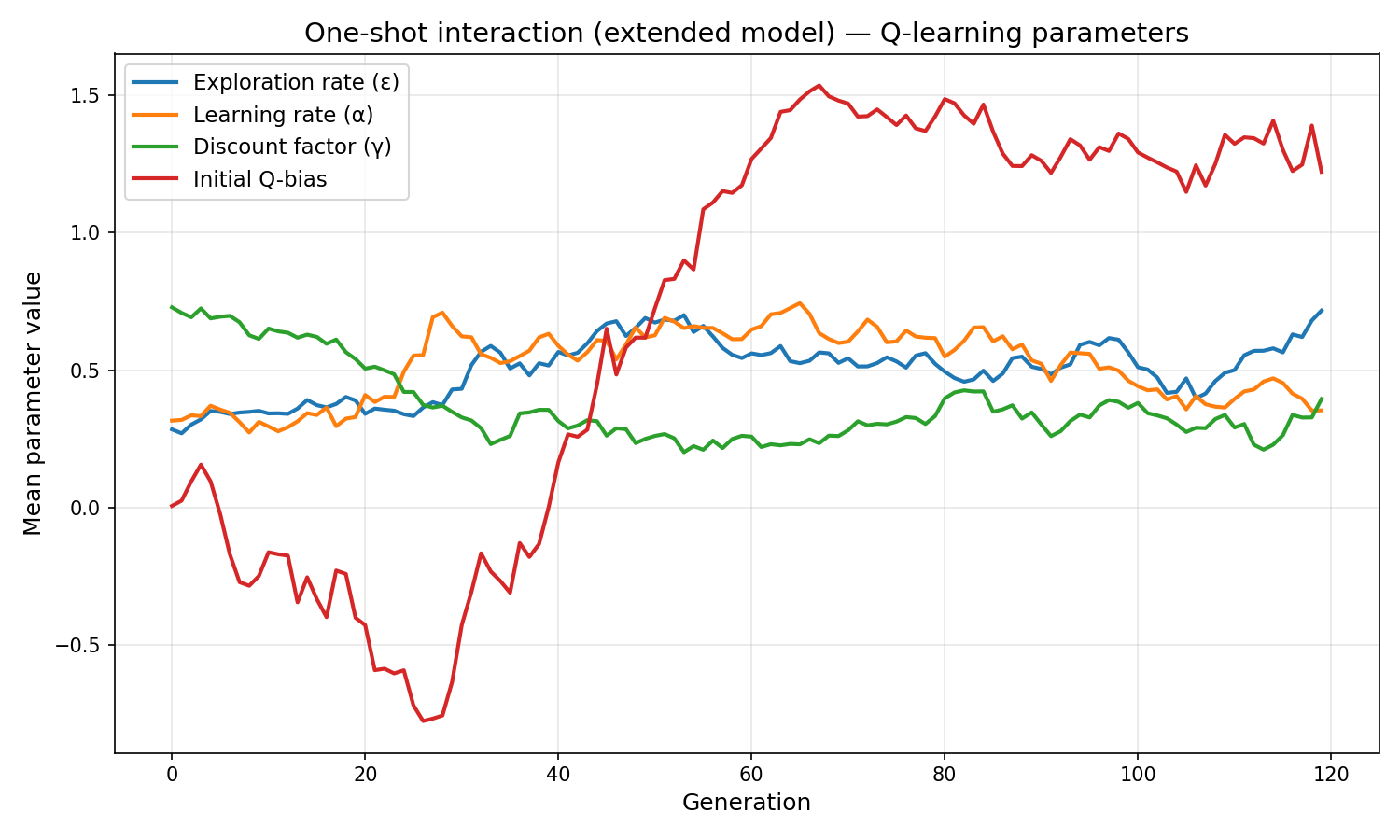
- Initial Q-bias goes negative (−0.52) in repeated play — agents are calibrated suspicious of strangers, relying on reputation to shift that prior upward for well-reputed partners.
Learning during a lifetime
Agents still update partner-specific Q-values, but now also:
- Reputation: after each interaction both agents update a publicly visible reputation score for their partner. Other agents read this score before meeting a stranger.
- Partner choice: before accepting an interaction, an agent checks the partner's reputation against its evolved
rejection_threshold. If the partner falls below it, the interaction is refused — the partner earns no payoff and loses further reputation. - Forgiveness: after a betrayal the Q-value for the defecting partner is penalised. Each subsequent round the penalty decays toward zero at a rate set by the evolved
forgiveness_rate, allowing the relationship to recover.
Evolution between generations
Agents inherit Model 2 parameters plus three social parameters:
rejection_thresholdforgiveness_ratereputation_weight
How the social parameters interact
- Reputation alone has no teeth unless agents can act on it.
- Partner choice gives reputation teeth: agents below the rejection threshold receive no benefit and lose further reputation.
- Forgiveness prevents partner choice from leading to permanent exclusion. Agents who start cooperating again gradually recover their Q-value relationship with a betrayed partner.
Together they form a coherent social-cognitive system: assess strangers by reputation, exclude persistent defectors, repair relationships with those who reform.
Results summary
| Metric | One-shot | Repeated |
|---|---|---|
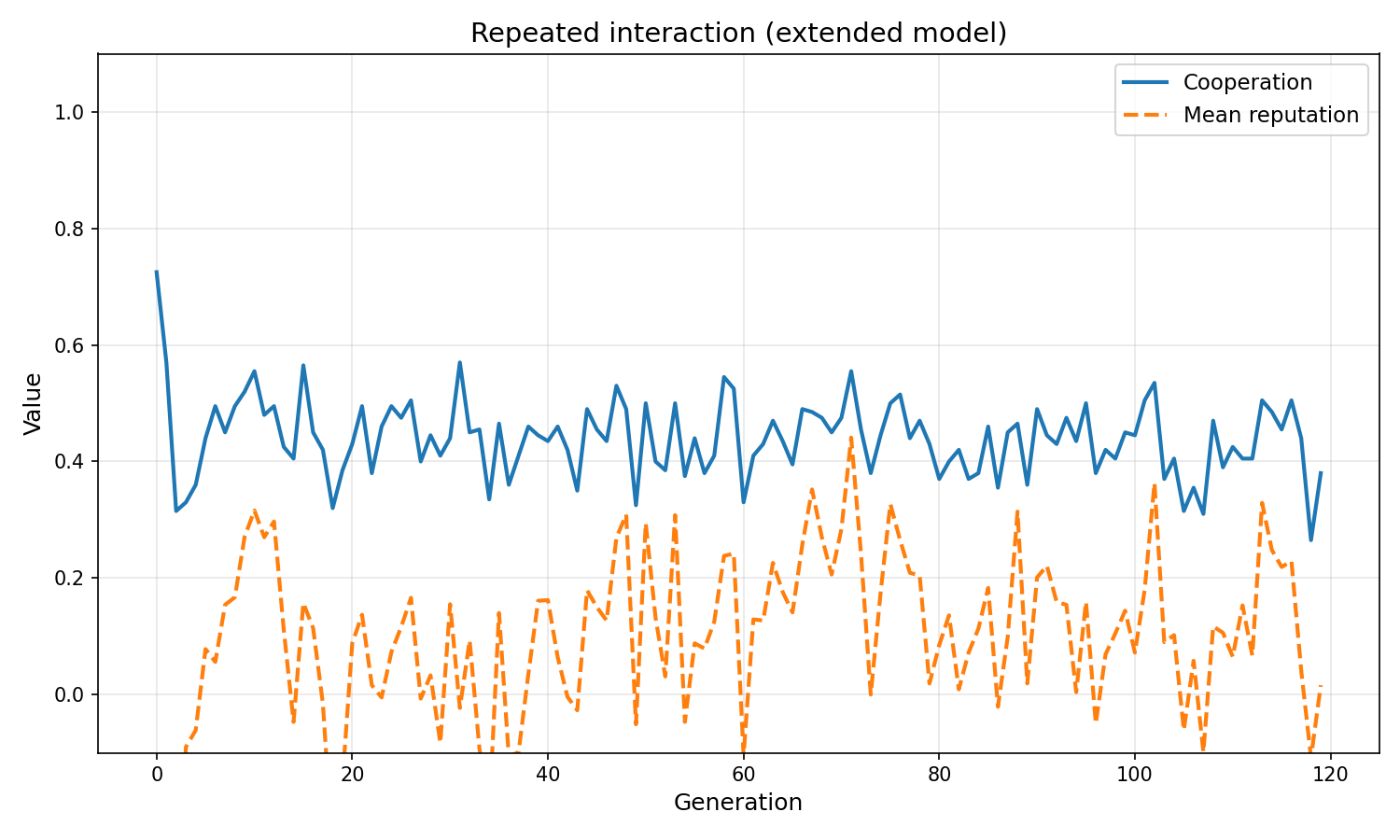
| Final cooperation rate | 0.450 | 0.380 |
| Final mean payoff | 4.100 | 288.120 |
| Final exploration rate | 0.717 | 0.073 |
| Final learning rate | 0.353 | 0.514 |
| Final discount factor | 0.395 | 0.581 |
| Final initial Q-bias | 1.222 | −0.519 |
| Final rejection threshold | −0.539 | −0.687 |
| Final forgiveness rate | 0.595 | 0.761 |
| Final reputation weight | 0.522 | 0.381 |
| Final mean reputation | 0.023 | 0.016 |
One-shot interaction
Repeated interaction
Summary
Cooperation rate is lower than in the basic Q-learning model (0.38 vs 0.56). This is not a failure of the model — it is a meaningful result. The rejection threshold evolves to be quite lenient (−0.69), meaning agents rarely exclude partners. But when they do, excluded agents lose reputation, which compounds. The resulting equilibrium is conditional cooperation with active monitoring, not unconditional cooperation.
Forgiveness evolves to be high (0.76) in the repeated case. Agents that recover quickly from betrayals maintain more cooperative relationships over time. This matches the human pattern: we forgive persistent partners faster than strangers, because the long-term value of the relationship outweighs the cost of a single defection.
Reputation weight evolves to be modest (0.38). Agents use public reputation as a weak prior for unknowns, but rely more on personal Q-learning history once they have direct experience. This mirrors how humans use social proof: it matters most when we have no personal experience with someone.
Initial Q-bias goes negative (−0.52) in repeated play. Agents start slightly pessimistic about new partners, but rely on their evolved reputation_weight to shift that prior upward for well-reputed strangers. This is calibrated suspicion — not naive trust, not paranoid rejection.
The extended model sacrifices some payoff compared to basic Q-learning because partner rejection has a cost — rejected interactions yield zero for both parties. But it gains robustness: defectors are excluded before they can extract many benefits. The three mechanisms form a coherent social-cognitive system that mirrors how human cooperation scales beyond small trusted groups.